
- cross-posted to:
- technology@lemmy.world
- cross-posted to:
- technology@lemmy.world
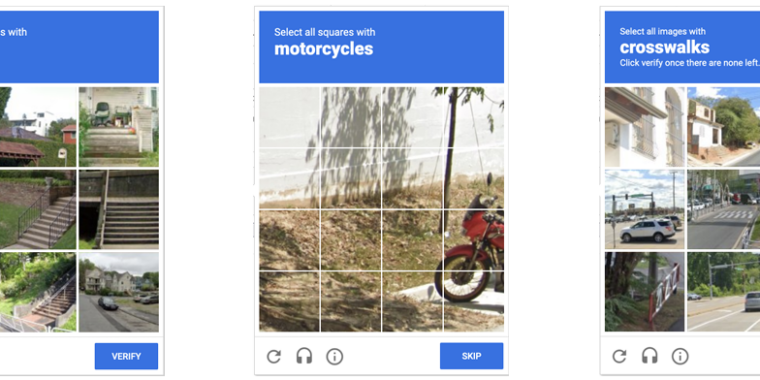
Anyone who has been surfing the web for a while is probably used to clicking through a CAPTCHA grid of street images, identifying everyday objects to prove that they’re a human and not an automated bot. Now, though, new research claims that locally run bots using specially trained image-recognition models can match human-level performance in this style of CAPTCHA, achieving a 100 percent success rate despite being decidedly not human.
ETH Zurich PhD student Andreas Plesner and his colleagues’ new research, available as a pre-print paper, focuses on Google’s ReCAPTCHA v2, which challenges users to identify which street images in a grid contain items like bicycles, crosswalks, mountains, stairs, or traffic lights. Google began phasing that system out years ago in favor of an “invisible” reCAPTCHA v3 that analyzes user interactions rather than offering an explicit challenge.
Despite this, the older reCAPTCHA v2 is still used by millions of websites. And even sites that use the updated reCAPTCHA v3 will sometimes use reCAPTCHA v2 as a fallback when the updated system gives a user a low “human” confidence rating.
This is actually a good sign for self driving. Google was using this data as a training set for Waymo. If AI is accurately identifying vehicles and traffic markings, it should be able to process interactions with them easier.
As I understand it, the point of those captchas was never really “bots can’t identify these things” (though you’re right on that it was used to train). They use cursor movement, clicks, and other behaviours while you’re solving it to detect if you are a bot or not.
The image choosing was always just to train their own bots
Since I started getting good at yosu and that fishing mini game in farmrpg I’ve been failing more captchas. I wonder if they’re related knowing this
It’s a combination.
Most captchas goals generally aren’t 100% prevention, it’s to put a workload in front, this makes spamming the site cost money, a bankrolled attempt could just as easily outsource the captchas to real humans.
The annoying thing is that they held us hostage for our free labor, but the results are proprietary for Google’s benefit only.
That training data ought to be forced to be made freely available to the public, since we’re the ones who actually created it.
Afaik this is precisely what the captcha data was intended for - training AI models. Originally leveraged machine learning. LLMs are a slightly different paradigm but same purpose and results here.
i hope you’re joking. please, tell me you’re joking?
Well reCaptcha v1 was used for the digitization of books. And that they proudly talked about.
But to be honest, the pictures were in fact used to dether bots. But also to teach selfdriving cars. I think I also remember a time they used to ask to fill in house numbers probably for their Maps accuracy.
Its never been confirmed by Google, so I may be wrong. It still tracks that the data harvesting company with a AI self driving car project would use free human labor to identify road hazards.
I was referring to the “This is actually a good sign for self driving” part of their comment.
The captcha circumvention arms race has been going on for over two decades, and every new type of captcha has and will continue to be broken as soon as it’s widely deployed enough that someone is motivated to spend the time to.
So, the notion that an academic paper about breaking the current generation of traffic-related captchas (something which the captcha solving industry has been doing for years with a pretty high success rate already) is “good news” for the autonomous vehicle industry (who has also been able to identify such objects well enough to continue existing and getting more regulatory approval for years now) is…
Not really. I’m not even sure what you’re disagreeing with based on the above comment.
My point is that if bog standard AI can accurately identify all of the road information from pictures, that is good news for self driving.
What was once a nearly impossible task for computers is now mundane, and can be used to improve safety/utility for self driving, especially for FOSS projects like comma.ai