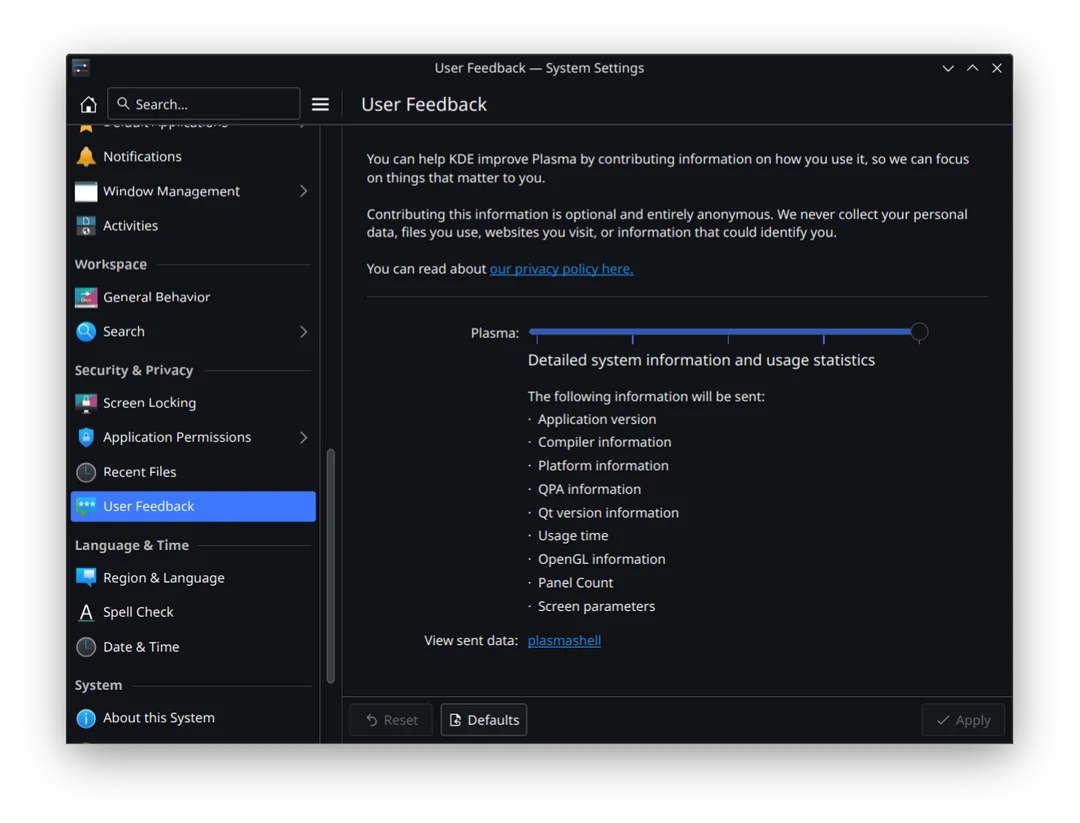
The issue is that this data can be used to fingerprint or de-anonomize users. Even if it’s just a big list of statistics, knowing how likely or unlikely a system change, setting change, version, etc. is can help greatly with a person looking to pin down users. They’ll know how likely a person with a specific pattern is the same person.
I’m glad it’s not distributed. If it was, I’d slide it all the way back to 0. Good intentions from the collectors doesn’t stop bad intentions of consumers
Datasets are still valuable for the broader community - there are many datasets out there, like the Brain project or the Oasis project which provide important insights into brain illnesses to train state of the art ML models on.
Any practitioner who wishes to work on those datasets is to sign a contract where they pledge not to try to identify any patient.
These kinds of contracts have been around for a while now, and if we could negotiate a situation as tricky as brain illnesses, I’m certain the same can be done for which version you have of a software, which particular config changes one has made or, say, if you use KActivities at all.

{kind=link}
Yup, it bugs me a lot that they refuse to disclose the data so that we all can learn from it (especially for statistics practitioners)
The issue is that this data can be used to fingerprint or de-anonomize users. Even if it’s just a big list of statistics, knowing how likely or unlikely a system change, setting change, version, etc. is can help greatly with a person looking to pin down users. They’ll know how likely a person with a specific pattern is the same person.
I’m glad it’s not distributed. If it was, I’d slide it all the way back to 0. Good intentions from the collectors doesn’t stop bad intentions of consumers
Datasets are still valuable for the broader community - there are many datasets out there, like the Brain project or the Oasis project which provide important insights into brain illnesses to train state of the art ML models on.
Any practitioner who wishes to work on those datasets is to sign a contract where they pledge not to try to identify any patient.
These kinds of contracts have been around for a while now, and if we could negotiate a situation as tricky as brain illnesses, I’m certain the same can be done for which version you have of a software, which particular config changes one has made or, say, if you use KActivities at all.