
The benchmark with many more metrics: https://www.phoronix.com/review/bcachefs-linux-67
Edit: The benchmarks were done with a debug variable set, which explains the weak IO.
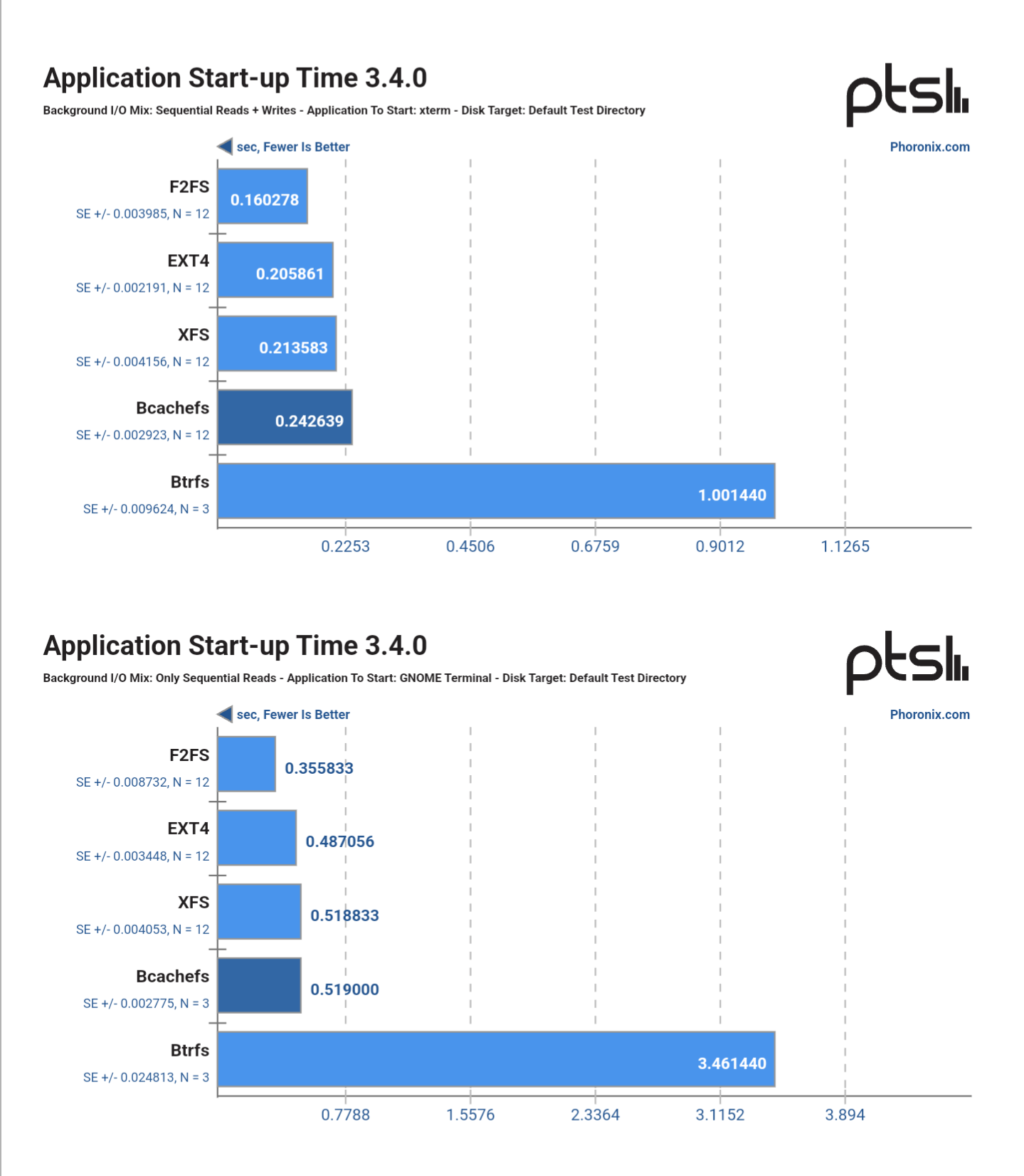
“Why does btrfs get a huge perf hit with background IO work?”
I’ve noticed a lot number of questions on reddit/etc. suddenly gets asked in that way (“why” in front of a statement). As an ESL I was confused for a while because I’ve been drilled in asking questions using auxiliary verbs.
I blame explanatory headlines. If you searched “why does [blank] happen?” you’d get articles like “why [blank] happens.” ESL speakers (and under-educated native speakers) bungle the difference. As this spreads, reddit and Stack Overflow start displacing tech-support blogs, and suddenly the headlines themselves are wrong.
I think it’s not btrfs that’s slow, it’s bcachefs that’s insanely fast. Bcachefs almost as fast as ext4 while having that many features is insane.
This screenshot is the only metric where btrfs is incredibly slow.
Bcachefs random and sequential writes and reads are much slower than other filesystems in this benchmark.
I have no idea how the actual real world performance will be. Bcachefs still misses a lot of features so I’ll continue to follow the development, hopefully including performance improvements.
Bcachefs sequential write performance in this out-of-the-box comparison was coming in at around half the speed of Btrfs while XFS, F2FS, and EXT4 were the fastest.
https://www.phoronix.com/review/bcachefs-linux-67/2
Edit: The benchmarks were done with a debug variable set, which explains the weak IO.
Wait, so the benchmarks mostly contradict claims that bcachefs is almost as fast as ext4 except in application startup time? What kind of test performed for that application startup time benchmark?
Note that in this benchmark, bcachefs had a debug variable turned on that allegedly severely hampered performance. Bcachefs has released an update to disable this variable but Phoronix hasn’t redone benchmarks yet. I wouldn’t put much value into any bcachefs-related comparisons from this current benchmark.
Interesting, that hopefully explains the weak IO troughput. Thank you.
The application startup test is designed to cold-load an application with heavy background IO going on.
Seems unreasonably slow to me that xterm would take a second to start. My two computers running kernel 6.7 are slow than the machine in the test, both have BTRFS on LUKS.
I tried a cold start of xterm on my older thinkpad with an NVMe drive at ~0.3s.
A cold start on my desktop (also NVMe), 0.08s.
I’m unable to reproduce. I wonder if he might’ve had a fresh install with some background operations grinding on, or some indexing going on.
What background IO load did you run?
Yeah; my somewhat up-to-date thinkbook with NVMe drive cold boots to Cinnamon desktop in under 8 seconds, terminal window opens in the blink of an eye. BTRFS is not without its problems, but they’re more along the lines of specific RAID configs not being what you’d wish for; I’ve never heard a complaint about speed before, and I’ve never had that problem myself.
Would like to see how much the background work is impacted over time. Seems like a scheduling issue to me
I was curious about this too. Definitely making me question some of my own thoughts and assumptions about btrfs.
It’s a single metric out of many for a file system, let’s see if someone investigates.
Hold up. I thought btrfs was better than ext4?
Filesystems aren’t so simple. Modern advanced filesystems like btrfs, zfs and bcachefs are more than just filesystems.
E.g. they include features like volume management, compression and sometimes encryption. Most features can also be achieved with for example ext4 + lvm + luks, but it’s nice to have all in one system with unified configuration.
tl;dr
Btrfs does more than ext4, which can have a negative performance impact, depending on the use case/metric. Usually the features gained by btrfs outweigh the small difference in performance imo.
Oh. So I didn’t need LVM and LUKS at my install?
Btrfs doesn’t do encryption, so luks is still necessary. LVM isn’t needed since btrfs subvolumes achieve the same in a more flexible way (no fixed size, snapshots).
Btrfs doesn’t have built in encryption, if you want to encrypt Btrfs you still need another layer (e.g. LUKS).
It’s mostly better, but not in every way. It has a lot of useful features, at a performance cost sometimes. A cost that historically wasn’t a problem with spinning hard drives and relatively slow SATA SSDs but will show up more on really fast NVMes.
The snapshots, it has to keep track of what’s been modified. Depending on the block size, an update of just a couple bytes can end up as a few 4k write because it’s Copy-on-Write and it has to update a journal and it has to update the block list of the file. But at the same time, copying a 50GB file is instantaneous on btrfs because of the same CoW feature. Most people find the snapshots more useful than eeking out every last bit of performance out of your drive.
Even ZFS, often considered to be the gold standard of filesystems, is actually kinda slow. But its purpose isn’t to be the fastest, its purpose is throwing an array of 200 drives at it and trusting it to protect you even against some media degradation and random bit flips in your storage with regular scrubs.
A couple nits to pick: BTRFS doesn’t use/need journaling because of its CoW nature - data on the disk is always correct because it doesn’t write data back over the same block it came from. Only once data is written successfully will the pointer be moved to the newly-written block. Also, instantaneous copies from BTRFS are actually due to reflinking instead of CoW (XFS can also do reflinking despite not being CoW, and ZFS didn’t have this feature until OpenZFS 2.2 which just released).
I agree with the ZFS bit and I’m firmly in the BTRFS/ZFS > Ext4/XFS/etc camp unless you have a specific performance usecase. The ability to scrub checksums of data is so invaluable in my opinion, not to mention all the other killer features. People have been running Ext4 systems for decades pretending that if Ext4 does not see the bitrot, the bitrot does not exist. (then BTRFS picks up a bad checksum and people scold it for being a bad filesystem)
People have been running Ext4 systems for decades pretending that if Ext4 does not see the bitrot, the bitrot does not exist. (then BTRFS picks up a bad checksum and people scold it for being a bad filesystem)
ZFS made me discover that my onboard SATA controller sucks and returns bad data occasionally under heavy load. My computer cannot complete a ZFS scrub without finding errors, every single time.
Ext4, bcache and mdadm never complained about it, ever. There was never any sign that something was wrong at all.
100% worth it if you care about your data. I can definitely feel the hit on my NVMe but it’s also doing so much more.
A file system and a raid setup all in one with facebook’s code for de-/compression … yet another piece of software that tries to do the work for several others.
ext4 will rarely have extreme loads unless all you do is backup and mirroring. For more accurate data read/write and better checks use xfs and external journaling. On M2 it is by far the fastest solution and far more secure than ext.
On magnetic disk there is physical location for each bit of data written, for ssd it is all virtual space handled by internal software simulating a magnetic drive. The variation from disk to disk is much higher than the sensitivity of the fs.
You want accuracy and reliability of data storage, use HDD and Raid!
RAID doesn’t checksum and heal the rotten data. It’s game over before you even have a filesystem on top of it, because said filesystem can’t directly access the underlying disks because of the RAID layer.
Errors will occur, and RAID has no way of handling it. You have a RAID1, disk 1 says it’s a 0, disk 2 says it’s a 1. Who’s right? RAID can’t tell, btrfs and ZFS can. RAID won’t even notice there’s a couple flipped bits, it’ll just pass them along. ZFS will just retry the read on both disks, pick the block that matches the checksum, and write the correct data back on the other disk. That’s why people with lots of data loves ZFS and RAIDZ.
The solution isn’t more reliable hardware, the solution software that can tell you and recover from your failing hardware.
I’m sure this is a specific workload that BTRFS struggles with that others handle just fine.
Other workloads BTRFS will be better, and in others it will be worse. There’s no one size fits all.
There are many other considerations besides startup speed, no? Filesystem reliability is a big one, and all the scrubbing and defragging features of btrfs are pretty neat
It probably has to do with the CoW nature of BTRFS compared to the others which don’t do CoW.
Bcachefs does use CoW iirc~
It does, it says so in the first sentence of the Wikipedia article
Ah, BCacheFS is also a lot less of a clusterfuck then BTRFS is too








{kind=link}